In recent years, generative model content production has advanced significantly, enabling high-quality user-controllable picture and video synthesis. Users may interactively generate and modify a high-resolution image using a 2D input label map and picture-to-image translation techniques. However, current image-to-image translation techniques only work in 2D and don’t explicitly consider the content’s underlying 3D structure. As seen in Figure 1, their goal is to make conditional image synthesis 3D-aware, enabling the creation of 3D material and the manipulation of viewpoints and attribute modification (for example, modifying the form of cars in 3D). It might be difficult to create 3D material dependent on human input. Obtaining huge datasets with coupled user inputs and intended 3D outputs is expensive for model training.
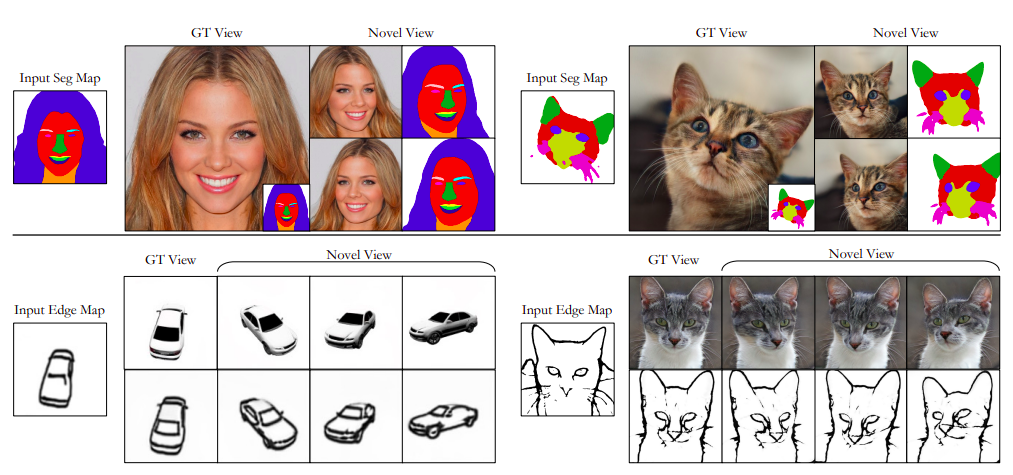
While a user may desire to describe the specifics of 3D objects using 2D interfaces from various angles, producing 3D content frequently necessitates multi-view user inputs. These inputs, meanwhile, could not be 3D-consistent, giving contradictory signals for the production of 3D content. To overcome these issues, they apply 3D neural scene representations to conditional generative models. They also contain semantic information in 3D to facilitate cross-view editing, which can subsequently be presented as 2D label maps from various angles. They only need 2D supervision in the form of picture reconstruction and adversarial losses to learn the aforementioned 3D representation.
Yet, their pixel-aligned conditional discriminator promotes the appearance and labels to look realistic while being pixel-aligned when rendered into new views. At the same time, the reconstruction loss assures the alignment between 2D user inputs and matching 3D material. They also suggest a cross-view consistency loss to require the latent codes to be constant across various perspectives. They concentrate on CelebAMask-HQ, AFHQ-cat, and shapenetcar datasets for 3D-aware semantic picture synthesis. Their approach effectively uses different 2D user inputs, such as segmentation maps and edge maps. Their approach surpasses several 2D and 3D baselines, including SEAN, SofGAN, and Pix2NeRF versions. Moreover, they minimize the effects of different design decisions and show how their methodology may be used in applications like cross-view editing and explicit user control over semantics and style.
To view further findings and code, visit their website. Their current approach has two significant drawbacks. First, it mostly concentrates on modeling the look and geometry of one type of item. Nevertheless, determining a canonical stance for generic scenes presents a difficult task. An interesting next step is to extend the approach to more complicated scene datasets with many objects. Second, their model training needs camera postures associated with each training image, while their approach does not require stances during inference time. The range of applications will be expanded even more by eliminating the need for pose information.
Check out the Paper, Project, and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 14k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.