Text-to-X models have grown rapidly recently, with most of the advancement being in text-to-image models. These models can generate photo-realistic images using the given text prompt.
mage generation is just one constituent of a comprehensive panorama of research in this field. While it is an important aspect, there are also other Text-to-X models that play a crucial role in different applications. For instance, text-to-video models aim to generate realistic videos based on a given text prompt. These models can significantly expedite the content preparation process.
On the other hand, text-to-3D generation has emerged as a critical technology in the fields of computer vision and graphics. Although still in its nascent stages, the ability to generate lifelike 3D models from textual input has garnered significant interest from both academic researchers and industry professionals. This technology has immense potential for revolutionizing various industries, and experts across multiple disciplines are closely monitoring its continued development.
Neural Radiance Fields (NeRF) is a recently introduced approach that allows for high-quality rendering of complex 3D scenes from a set of 2D images or a sparse set of 3D points. Several methods have been proposed to combine text-to-3D models with NeRF to obtain more pleasant 3D scenes. However, they often suffer from distortions and artifacts and are sensitive to text prompts and random seeds.
In particular, the 3D-incoherence problem is a common issue where the rendered 3D scenes produce geometric features that belong to the frontal view multiple times at various viewpoints, resulting in heavy distortions to the 3D scene. This failure occurs due to the 2D diffusion model’s lack of awareness regarding 3D information, especially the camera pose.
What if there was a way to combine text-to-3D models with the advancement in NeRF to obtain realistic 3D renders? Time to meet 3DFuse.

3DFuse is a middle-ground approach that combines a pre-trained 2D diffusion model imbued with 3D awareness to make it suitable for 3D-consistent NeRF optimization. It effectively injects 3D awareness into pre-trained 2D diffusion models.
3DFuse starts with sampling semantic code to speed up the semantic identification of the generated scene. This semantic code is actually the generated image and the given text prompt for the diffusion model. Once this step is done, the consistency injection module of 3DFuse takes this semantic code and obtains a viewpoint-specific depth map by projecting a coarse 3D geometry for the given viewpoint. They use an existing model to achieve this depth map. The depth map and the semantic code are then used to inject 3D information into the diffusion model.
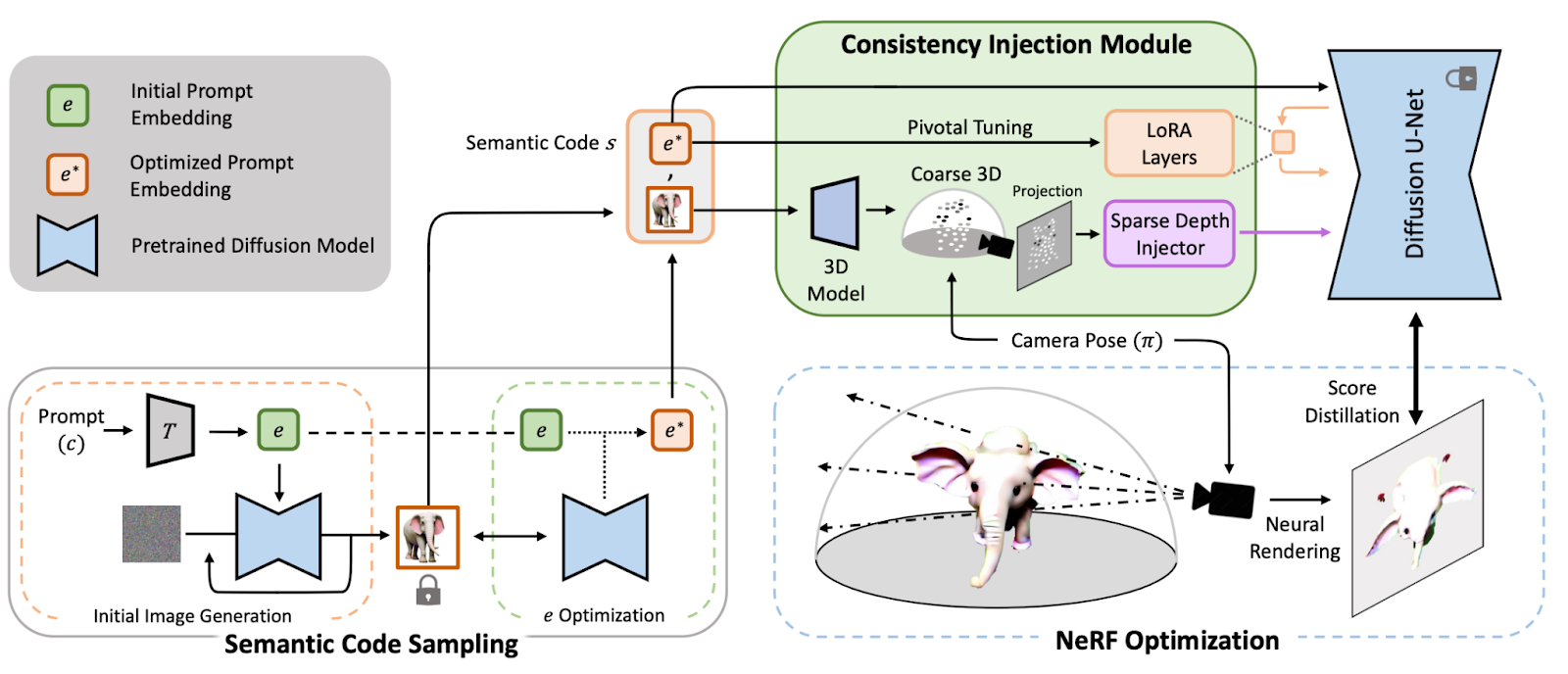
The problem here is the predicted 3D geometry is prone to errors, and that could alter the quality of the generated 3D model. Therefore, it should be handled before proceeding further into the pipeline. To solve this issue, 3DFuse introduces a sparse depth injector that implicitly knows how to correct problematic depth information.
By distilling the score of the diffusion model that produces 3D-consistent images, 3DFuse stably optimizes NeRF for view-consistent text-to-3D generation. The framework achieves significant improvement over previous works in generation quality and geometric consistency.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 18k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
???? Check Out 100’s AI Tools in AI Tools Club
![]()
Ekrem C?etinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.