Meet Magnushammer: A Transformer-based Approach to Premise Selection
Artificial intelligence’s main focus has been on automating mathematical reasoning. More recently, machine learning has greatly benefited both informal and formal theorem proving. The latter method, which they use in this research, enables proof assistants to interact with machine learning models to verify proofs produced by such models automatically. Mathematics is hierarchical because it builds upon and bootstraps from an existing body of knowledge. As a result, proving a mathematical assertion is seen as a creative process requiring, among other things, intuition, insights, and a wise choice of tactics.
These skills can assist in selecting pertinent facts that, when applied at a certain stage, develop the case and finally point to the desired result. Premise selection is the term used to describe this procedure in automated reasoning systems. Premise selection has been addressed by several tools, including a family of devices known as “hammers” that include Automatic Theorem Provers into interactive proof helpers. One such tool, Sledgehammer, rose to popularity with Isabelle, where it was used to produce a sizable chunk of the Archive of Formal Proofs, Isabelle’s proof corpus.
Although hammers have been implemented into other proof assistants, not all proof assistants now support them. This is because hammers implementation is difficult owing to the variety of evidence object structures and the intricate translation procedures needed across various logics. So, there is a critical need for an efficient premise selection tool that can operate across all proof helpers with little need for customization. In this work, researchers from GoogleAI present Magnushammer, a general-purpose, data-driven transformer-based premise selection tool. They show that it can conduct premise selection efficiently and with little domain-specific expertise.
Magnushammer has two retrieval phases, each trained via contrastive learning. At the SELECT stage, given a proof state, they select the 1024 premises from the theorem that are most pertinent to the proof (as determined by the cosine similarity of their embeddings) (database up to 433K). In the second step, RERANK, they re-rank the retrieved premises using more precise but costly processing. Using a transformer architecture, they allowed the proof state tokens to directly attend to the retrieved premise tokens, producing a relevance score. Magnushammer surpasses Sledgehammer’s 38.3% proof rate by a wide margin, scoring a 59.5% on the PISA benchmark.
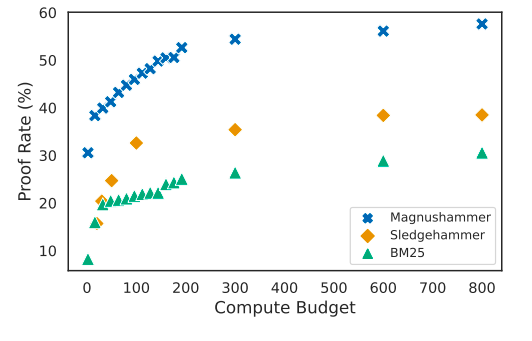
They show that given any compute budget, the proof rate of Magnushammer significantly outperforms that of Sledgehammer, as illustrated in Figure 1. A neural-symbolic model called Thor has a Sledgehammer component that they replace with a Magnushammer component, increasing the state-of-the-art proof rate from 57.0% to 71.0%. The Isabelle theorem prover and its human-proof libraries were mined for a dataset of premise selection to get these findings. The collection includes 433K distinct premises among 4.4M examples of premise selection instances. This is the largest premise selection dataset of its sort that they are aware of.
Their contributions can be sumarised as follows:
• As a general, data-driven strategy for premise selection, they suggest using transformers trained contrastively. Magnushammer, the approach they developed, greatly outperforms Sledgehammer, the most widely used symbolic premise selection tool, with a 59.5% proof rate on the PISA benchmark.
• To their knowledge, they extracted and made the largest premise selection dataset available. It has 433K distinct premises and 4.4M premise selection instances. They anticipate that this dataset will be useful for advancing present and future research in the field.
• They examine the scalability of Magnushammer concerning model size, dataset size, and computing budget for inference time. Their analysis suggests that adding more computer power might lead to even greater gains.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.