Meet Text2Room: A New AI Method For Generating Room-Scale Textured 3D Meshes From A Given Text Prompt As Input
Mesh representations of 3D sceneries are essential to many applications, from developing AR/VR assets to computer graphics. However, making these 3D assets is still laborious and demands a lot of skill. Recent efforts have utilized generative models, such as diffusion models, to effectively produce high-quality pictures from a text in the 2D realm. These techniques successfully contribute to the democratization of content production by greatly lowering the obstacles to producing pictures that include a user’s chosen content. A new area of research has attempted to use comparable techniques to generate 3D models from the text. However, current methods have drawbacks and need more generality of 2D text-to-image models.
Dealing with the dearth of 3D training data is one of the main difficulties in creating 3D models since 3D datasets are much smaller than those used in many other applications, such as 2D image synthesis. For instance, methods that employ 3D supervision directly are frequently restricted to datasets of basic forms, like ShapeNet. Recent techniques overcome these data constraints by formalizing 3D creation as an iterative optimization problem in the picture domain, enhancing the expressive potential of 2D text-to-image models into 3D. The capacity to produce arbitrary (neural) forms from text is demonstrated by their ability to construct 3D objects stored in a radiance field representation. Unfortunately, expanding on these techniques to produce 3D structure and texture at room size can be challenging.
Making sure that the output is dense and cohesive across outward-facing viewpoints and that these views include all necessary features, such as walls, floors, and furniture, is difficult when creating enormous scenes. A mesh remains a preferred representation for several end-user activities, including rendering on affordable technology. Researchers from TU Munich and University of Michigan suggest a technique that extracts scene-scale 3D meshes from commercially available 2D text-to-image models to solve these drawbacks. Their technique employs inpainting and monocular depth perception to create a scene iteratively. Using a depth estimate technique, they make the first mesh by creating a picture from text and back projecting it into three dimensions. The model is then repeatedly rendered from fresh angles.
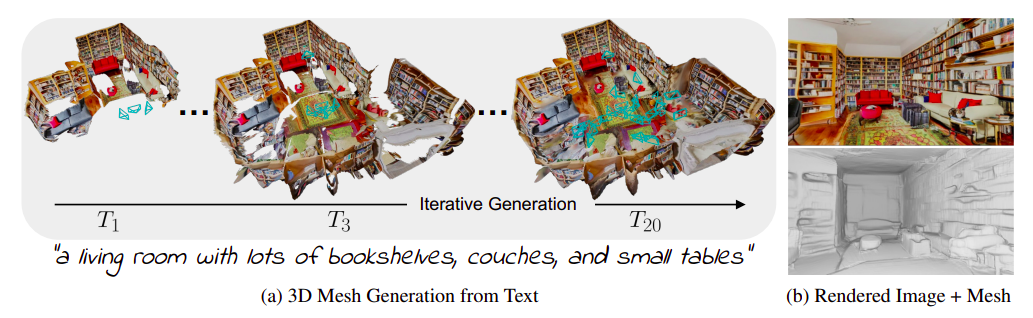
For each, they inpaint any gaps in the displayed pictures before fusing the created content into the mesh (Fig. 1a). Two key design factors for their iterative generation approach are how they select the views and how they integrate the created scene material with the current geometry. They initially choose perspectives from predetermined trajectories that will cover a significant portion of the scene material, and they then select viewpoints adaptively to fill in any gaps. To produce seamless transitions when combining generated content with the mesh, they align the two depth maps and remove any areas of the model with distorted textures.
Combined, these choices provide sizable, scene-scale 3D models (Fig. 1b) that can depict a variety of rooms and have appealing materials and uniform geometry. So, their contributions are as follows:
• A technique that uses 2D text-to-image models and monocular depth estimation to lift frames into 3D in iterative scene creation.
• A method that creates 3D meshes of room-scale interior scenes with beautiful textures and geometry from any text input. They can produce seamless, undistorted geometry and textures using their suggested depth alignment and mesh fusion methods.
• A two-stage customized perspective selection that samples camera poses from ideal angles to first lay out the furnishings and layout of the area and then fill in any gaps to provide a watertight mesh.
Check out the Paper, Project, and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 16k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.