Understanding a holistic 3D picture is a significant challenge for autonomous vehicles (AV) to perceive. It directly influences later activities like planning and map creation. The lack of sensor resolution and the partial observation caused by the small field of vision and occlusions make it challenging to get precise and comprehensive 3D information about the actual environment. Semantic scene completion (SSC), a method for jointly inferring the whole scene geometry and semantics from sparse observations, was offered to solve the problems. Scene reconstruction for viewable areas and scene hallucination for obstructed sections are two subtasks an SSC solution must handle concurrently. Humans readily reason about scene geometry and semantics based on imperfect observations, which supports this endeavor.
Nevertheless, modern SSC techniques still lag below human perception in driving scenarios in terms of performance. LiDAR is regarded as a main modality by most current SSC systems to provide precise 3D geometric measurements. Yet, cameras are more affordable and offer better visual indications of the driving environment, but LiDAR sensors are more costly and less portable. This inspired the investigation of camera-based SSC solutions, which were initially put forth in the ground-breaking work of MonoScene. MonoScene uses dense feature projection to convert 2D picture inputs to 3D. Yet, such a projection gives empty or occluded voxels 2D characteristics from the viewable areas. An empty voxel covered by a car, for instance, will nevertheless receive the visual characteristic of the automobile.
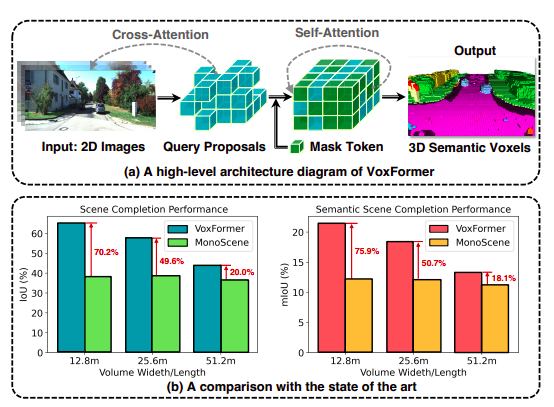
As a result, the 3D features created have poor performance regarding geometric completeness and semantic segmentation—their involvement. VoxFormer, in contrast to MonoScene, views 3D-to-2D cross-attention as a representation of sparse queries. The suggested design is inspired by two realizations: (1) sparsity in 3-D space: Since a significant portion of 3-D space is typically empty, a sparse representation rather than a dense one is undoubtedly more effective and scalable. (2) reconstruction-before-hallucination: The 3D information of the non-visible region can be better completed using the reconstructed visible areas as starting points.
In brief, they made the following contributions to this effort:
• A cutting-edge two-stage system that transforms photos into a whole 3D voxelized semantic scene.
• An innovative 2D convolution-based query proposal network that produces trustworthy inquiries from picture depth.
• A unique Transformer that produces a full 3D scene representation and is akin to the masked autoencoder (MAE).
• As seen in Fig. 1(b), VoxFormer advances the state-of-the-art camera-based SSC .
VoxFormer comprises two stages: stage 1 suggests a sparse set of occupied voxels, and stage 2 completes the scene representations beginning from stage 1’s recommendations. Stage 1 is class-agnostic, while stage 2 is class-specific. As illustrated in Fig. 1(a), Stage-2 is built on a unique sparse-to-dense MAE-like design. In particular, stage-1 contains a lightweight 2D CNN-based query proposal network that reconstructs the scene geometry using picture depth. Then, throughout the whole field of vision, it suggests a sparse collection of voxels using preset learnable voxel queries.
They first strengthen their featurization by enabling the suggested voxels to pay attention to the picture observations. The remaining voxels will then be processed by self-attention to finish the scene representations for per-voxel semantic segmentation after the non-proposed voxels are connected to a learnable mask token. VoxFormer provides state-of-the-art geometric completion and semantic segmentation performance, according to extensive experiments on the large-scale SemanticKITTI dataset. More critically, as demonstrated in Fig. 1, the benefits are large in safety-critical short-range locations.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.