

It is customary in fluid mechanics to distinguish between the Lagrangian and Eulerian flow field formulations. According to Wikipedia, “Lagrangian specification of the flow field is an approach to studying fluid motion where the observer follows a discrete fluid parcel as it flows through space and time. The pathline of a parcel may be determined by graphing its location over time. This might be pictured as floating along a river while seated in a boat. The Eulerian specification of the flow field is a method of analyzing fluid motion that places particular emphasis on the locations in the space through which the fluid flows as time passes. Sitting on a riverbank and observing the water pass a fixed point will help you visualize this.
These ideas are crucial to understanding how they examine recordings of human action. According to the Eulerian perspective, they would concentrate on feature vectors at certain places, such as (x, y) or (x, y, z), and consider historical evolution while remaining stationary in space at the spot. According to the Lagrangian perspective, they would follow, let’s say, a human across spacetime and the related feature vector. For example, older research for activity recognition frequently employed the Lagrangian viewpoint. However, with the development of neural networks based on 3D spacetime convolution, the Eulerian viewpoint has become the norm in cutting-edge methods like SlowFast Networks. The Eulerian perspective has been maintained even after the changeover to transformer systems.
This is significant because it provides us a chance to reexamine the query, “What should be the counterparts of words in video analysis?” during the tokenization process for transformers. Image patches were recommended by Dosovitskiy et al. as a good option, and the extension of that concept to video implies that spatiotemporal cuboids might be suitable for video as well. Instead, they adopt the Lagrangian perspective for examining human behavior in their work. This makes it clear that they think about an entity’s course across time. In this case, the entity might be high-level, like a human, or low-level, like a pixel or patch. They opt to function on the level of “humans-as-entities” because they are interested in comprehending human behavior.
To do this, they use a technique that analyses a person’s movement in a video and utilizes it to identify their activity. They can retrieve these trajectories using the recently released 3D tracking techniques PHALP and HMR 2.0. Figure 1 illustrates how PHALP recovers person tracks from video by elevating individuals to 3D, allowing them to link people across several frames and access their 3D representation. They employ these 3D representations of people?their 3D poses and locations?as the fundamental elements of each token. This allows us to construct a flexible system where the model, in this case, a transformer, accepts tokens belonging to various individuals with access to their identity, 3D posture, and 3D location as input. We may learn about interpersonal interactions by using the 3D locations of the persons in the scenario.
Their tokenization-based model surpasses earlier baselines that just had access to posture data and can use 3D tracking. Although the evolution of a person’s position through time is a powerful signal, some activities need additional background knowledge about the surroundings and the person’s look. As a result, it’s crucial to combine stance with data about person and scene appearance that is derived directly from pixels. To do this, they additionally employ cutting-edge action recognition models to supply supplementary data based on the contextualized appearance of the people and the environment in a Lagrangian framework. They specifically record the contextualized appearance attributes localized around each track by intensively running such models across the route of each track.
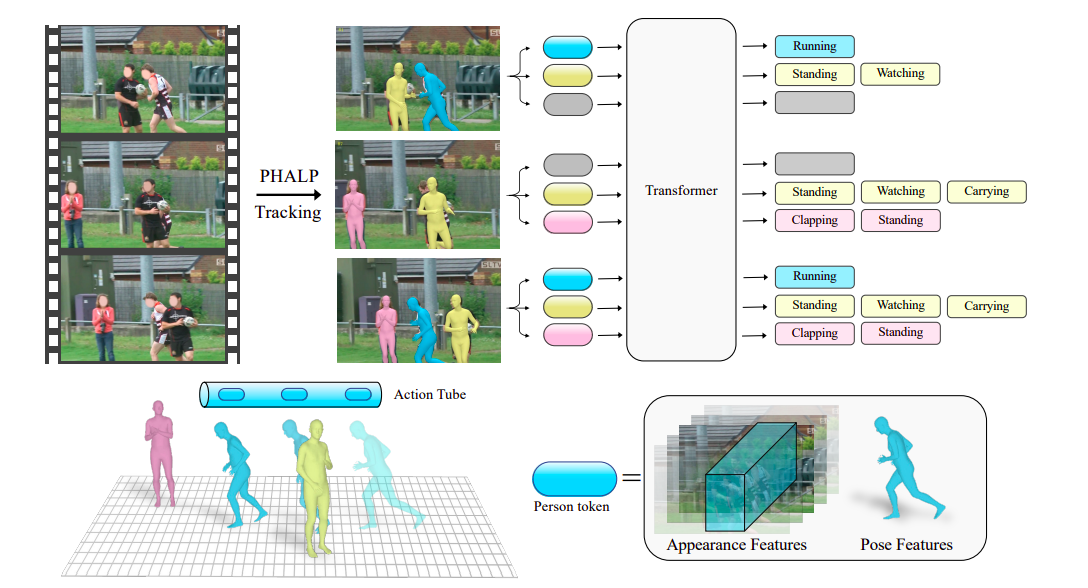
Their tokens, which are processed by action recognition backbones, contain explicit information on the 3D stance of the individuals as well as highly sampled appearance data from the pixels. On the difficult AVA v2.2 dataset, their whole system exceeds the prior state of the art by a significant margin of 2.8 mAP. Overall, their key contribution is the introduction of a methodology that emphasizes the benefits of tracking and 3D poses for comprehending human movement. Researchers from UC Berkeley and Meta AI suggest a Lagrangian Action Recognition with Tracking (LART) method that uses people’s tracks to forecast their actions. Their baseline version outperforms earlier baselines that used posture information using trackless trajectories and 3D pose representations of the persons in the video. Additionally, they show that the standard baselines that solely consider appearance and context from the video may be readily integrated with the suggested Lagrangian viewpoint of action detection, yielding notable improvements over the predominant paradigm.