

Large Language Models (LLMs) have emerged as game changers in the natural language processing domain. They are becoming a key part of our daily lives. The most famous example of an LLM is ChatGPT, and it is safe to assume almost everybody knows about it at this point, and most of us use it on a daily basis.
LLMs are characterized by their huge size and capacity to learn from vast amounts of text data. This enables them to generate coherent and contextually relevant human-like text. These models are built based on deep learning architectures, such as GPT (Generative Pre-trained Transformer) and BERT (Bidirectional Encoder Representations from Transformers), which uses attention mechanisms to capture long-range dependencies in a language.
By leveraging pre-training on large-scale datasets and fine-tuning on specific tasks, LLMs have shown remarkable performance in various language-related tasks, including text generation, sentiment analysis, machine translation, and question-answering. As LLMs continue to improve, they hold immense potential to revolutionize natural language understanding and generation, bridging the gap between machines and human-like language processing.
On the other hand, some people thought LLMs were not using their full potential as they are limited to text input only. They have been working on extending the potential of LLMs beyond language. Some of the studies have successfully integrated LLMs with various input signals, such as images, videos, speech, and audio, to build powerful multi-modal chatbots.
Though, there is still a long way to go here as most of these models lack the understanding of the relationships between visual objects and other modalities. While visually-enhanced LLMs can generate high-quality descriptions, they do so in a black-box manner without explicitly relating to the visual context.
Establishing an explicit and informative correspondence between text and other modalities in multi-modal LLMs can enhance user experience and enable a new set of applications for these models. Let us meet with BuboGPT, which tackles this limitation.
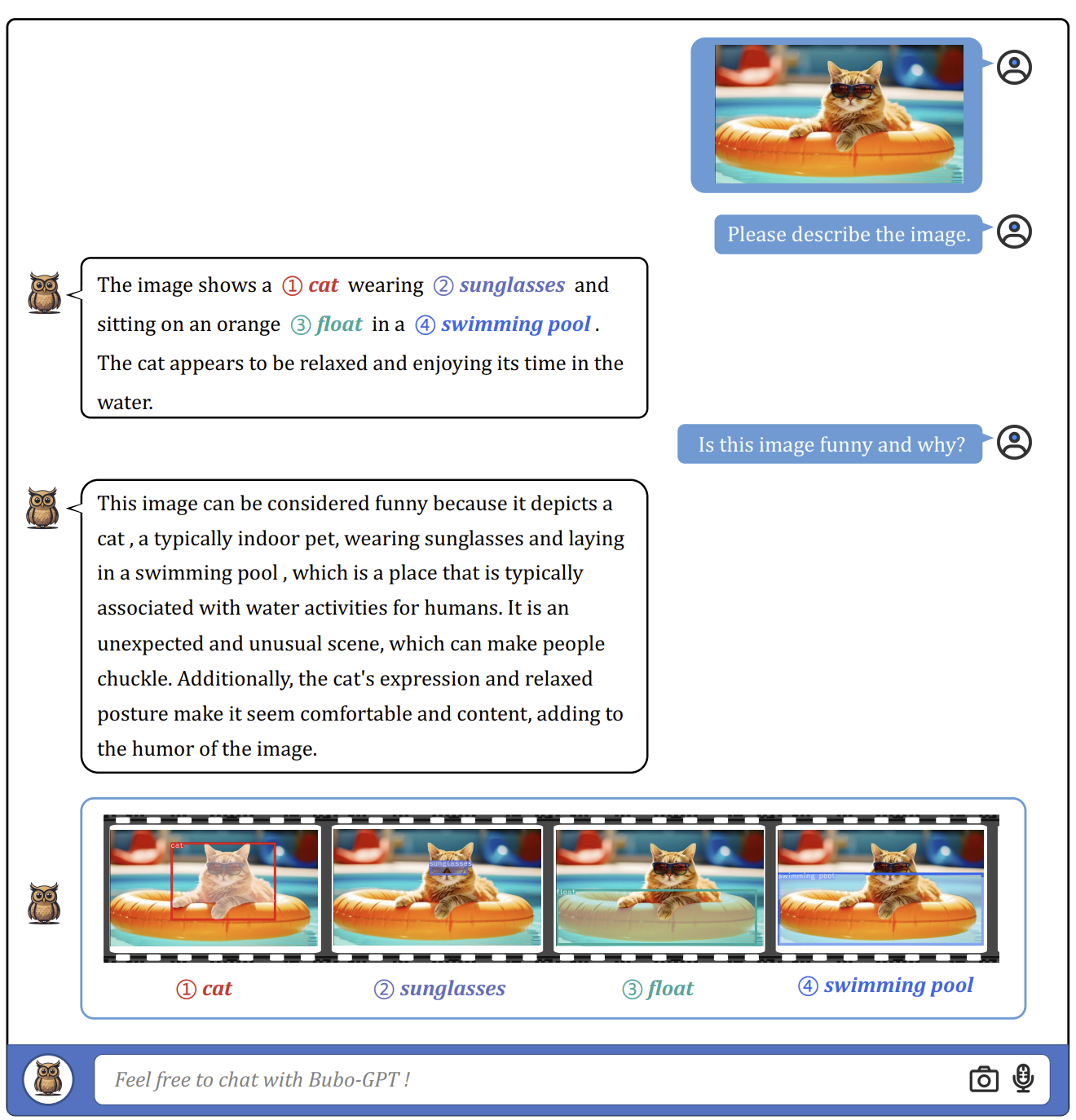
BuboGPT is the first attempt to incorporate visual grounding into LLMs by connecting visual objects with other modalities. BuboGPT enables joint multi-modal understanding and chatting for text, vision, and audio by learning a shared representation space that aligns well with pre-trained LLMs.
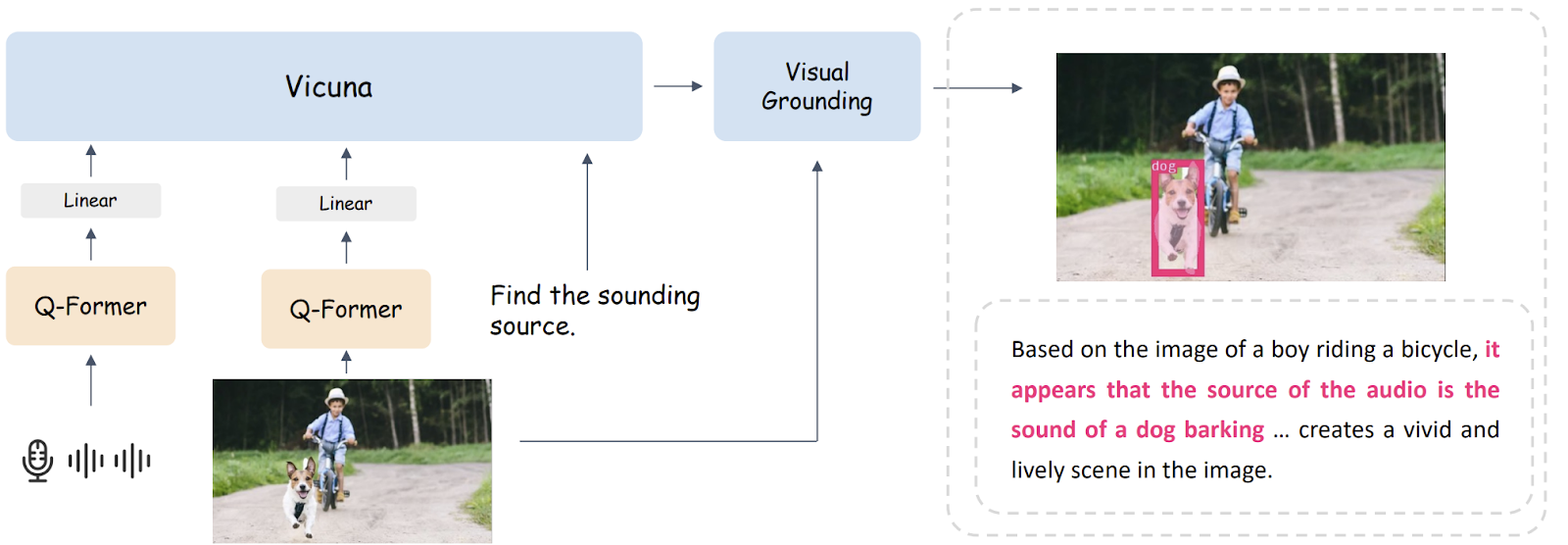
Visual grounding is not an easy task to achieve, so that plays a crucial part in BuboGPT?s pipeline. To achieve this, BuboGPT builds a pipeline based on a self-attention mechanism. This mechanism establishes fine-grained relations between visual objects and modalities.
The pipeline includes three modules: a tagging module, a grounding module, and an entity-matching module. The tagging module generates relevant text tags/labels for the input image, the grounding module localizes semantic masks or boxes for each tag, and the entity-matching module uses LLM reasoning to retrieve matched entities from the tags and image descriptions. By connecting visual objects and other modalities through language, BuboGPT enhances the understanding of multi-modal inputs.
To enable a multi-modal understanding of arbitrary combinations of inputs, BuboGPT employs a two-stage training scheme similar to Mini-GPT4. In the first stage, it uses ImageBind as the audio encoder, BLIP-2 as the vision encoder, and Vicuna as the LLM to learn a Q-former that aligns vision or audio features with language. In the second stage, it performs multi-modal instruct tuning on a high-quality instruction-following dataset.
The construction of this dataset is crucial for the LLM to recognize provided modalities and whether the inputs are well-matched. Therefore, BuboGPT builds a novel high-quality dataset with subsets for vision instruction, audio instruction, sound localization with positive image-audio pairs, and image-audio captioning with negative pairs for semantic reasoning. By introducing negative image-audio pairs, BuboGPT learns better multi-modal alignment and exhibits stronger joint understanding capabilities.