

Diffusion models are something you should be familiar with at this point. They have been the key topic in the AI domain for the last year. These models showed remarkable success in image generation, and they opened an entirely new page.
We are in the text-to-image generation era, and they improve daily. Diffusion-based generative models, such as MidJourney, have demonstrated incredible capabilities in synthesizing high-quality images from text descriptions. These models use large-scale image-text datasets, enabling them to generate diverse and realistic visual content based on textual prompts.
The rapid advancement of text-to-image models has led to remarkable advancements in image editing and content generation. Nowadays, users can control various aspects of both generated and real images. This enables them to express their ideas better and demonstrate the outcome in a relatively rapid way instead of spending days in manual drawing.
However, the story is different when it comes to applying these exciting breakthroughs to the realm of videos. We have relatively slower progress here. Although large-scale text-to-video generative models have emerged, showcasing impressive results in generating video clips from textual descriptions, they still face limitations regarding resolution, video length, and the complexity of video dynamics they can represent.
One of the key challenges in using an image diffusion model for video editing is to ensure that the edited content remains consistent across all video frames. While existing video editing methods based on image diffusion models have achieved global appearance coherency by extending the self-attention module to include multiple frames, they often fall short of achieving the desired level of temporal consistency. This leaves professionals and semi-professionals to resort to elaborate video editing pipelines involving additional manual work.
Let us meet with TokenFlow, an AI model that utilizes the power of a pre-trained text-to-image model to enable text-driven editing of natural videos.
The main goal of TokenFlow is to generate high-quality videos that adhere to the target edit expressed by an input text prompt while preserving the spatial layout and motion of the original video.

TokenFlow is introduced to tackle the temporal inconsistency. It explicitly enforces the original inter-frame video correspondences on the edit. By recognizing that natural videos contain redundant information across frames, TokenFlow builds upon the observation that the internal representation of the video in the diffusion model exhibits similar properties.
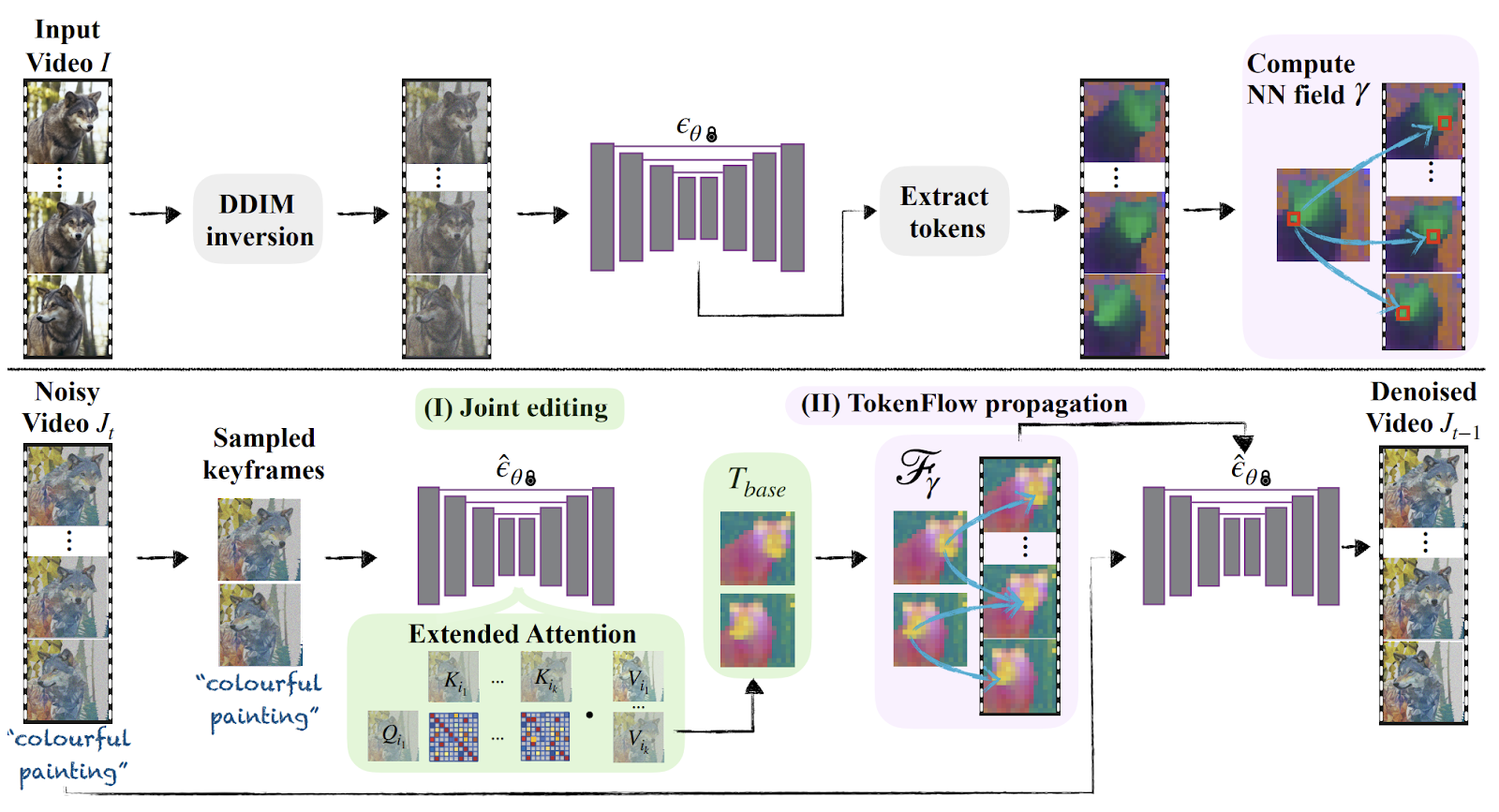
This insight serves as the pillar of TokenFlow, enabling the enforcement of consistent edits by ensuring that the features of the edited video are consistent across frames. This is achieved by propagating the edited diffusion features based on the original video dynamics, leveraging the generative prior to the state-of-the-art image diffusion model without the need for additional training or fine-tuning. TokenFlow also works seamlessly in conjunction with an off-the-shelf diffusion-based image editing method.