

Revolutionary advances in machine learning (ML) algorithms have empowered many AI-powered applications in various industries, such as e-commerce, finance, manufacturing, and medicine. However, developing real-world ML systems in complex data settings can be challenging, as shown by numerous high-profile failures due to biases in the data or algorithms.
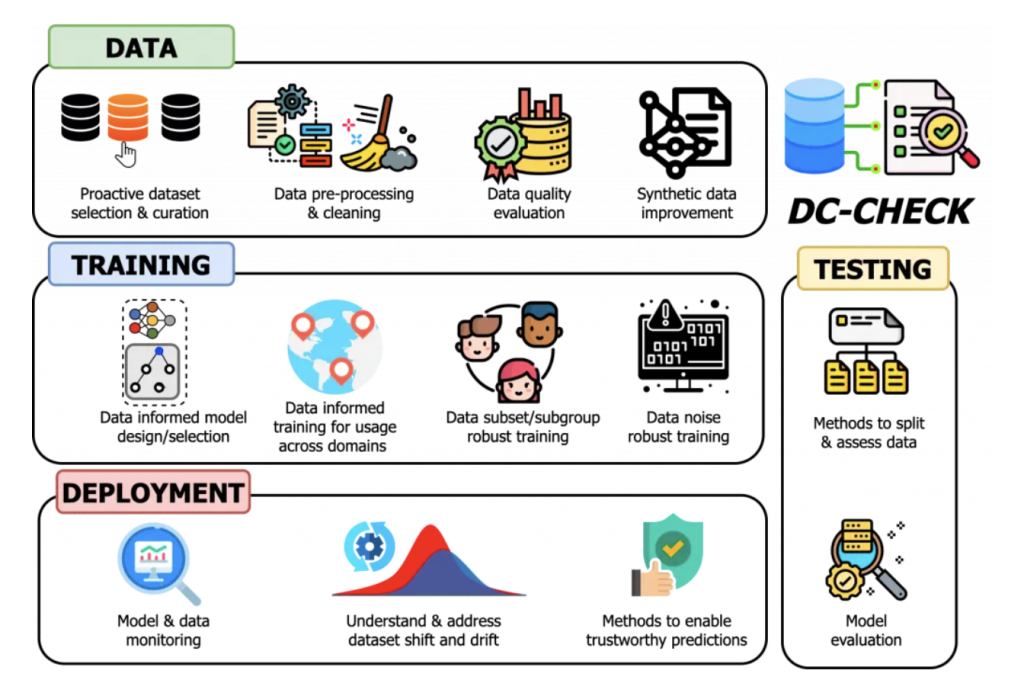
To address this issue, a team of researchers from the University of Cambridge and UCLA have introduced a new data-centric AI framework called DC-Check; which aims to emphasize the importance of the data used to train machine learning algorithms. DC-Check is an actionable checklist-style framework that provides a set of questions and practical tools to guide practitioners and researchers to think critically about the impact of data on each stage of the ML pipeline: Data, Training, Testing, and Deployment.
According to the researchers, the current approach to machine learning is model-centric, where the focus is on model iteration and improvement to achieve better predictive performance. However, this approach often undervalues the importance of the data across the ML lifecycle. In contrast, data-centric AI views data as the key to building reliable ML systems and seeks to systematically improve the data used by these systems. They define data-centric AI as: ?Data-centric AI encompasses methods and tools to systematically characterize, evaluate, and monitor the underlying data used to train and evaluate models?. By focusing on the data, we aim to create AI systems that are not only highly predictive but also reliable and trustworthy,” the researchers wrote in their paper.
The researchers point out that while there is great interest in data-centric AI, there currently is no standardized process when it comes to designing data-centric AI systems, making it difficult for practitioners to apply it to their work.
DC-Check solves this challenge as the first standardized framework to engage with data-centric AI. The DC-Check checklist provides a set of questions to guide users to think critically about the impact of data on each stage of the pipeline, along with practical tools and techniques. It also highlights open challenges for the research community to address.
DC-Check covers the four key stages of the machine learning pipeline: Data, Training, Testing, and Deployment. Under the Data stage, DC-Check encourages practitioners to consider proactive data selection, data curation, data quality evaluation, and synthetic data to improve the quality of data used for model training. Under Training, DC-Check promotes data-informed model design, domain adaptation, and group robust training. Testing considerations include informed data splits, targeted metrics and stress tests, and evaluation on subgroups. Finally, Deployment considerations encompass data monitoring, feedback loops, and trustworthiness methods like uncertainty estimation.
While the checklist has a target audience of practitioners and researchers, it is mentioned that DC-Check can also be used by organizational decision-makers, regulators, and policymakers to make informed decisions about AI systems.