Not how effectively the model maximizes the training goal, but rather how well the predictions are matched with the task risk, i.e., the model’s performance on the intended usage is the primary criterion for success when dealing with complicated outputs in computer vision. As a community, they iterate on model architectures, data, optimization, sampling techniques, postprocessing, etc., to better this alignment. For instance, in object detection, researchers apply set-based global loss, non-maximum suppression postprocessing, or even change the input data to create models that perform better during testing. Even though these methods produce sizable improvements, they are frequently extremely specialized to the job and technique at hand and only tangentially optimize for task risk.
This issue is not brand-new. It has received substantial research in reinforcement learning (RL) and natural language processing (NLP). It isn’t easy to construct an optimization target for tasks with less obvious aims, such as translation or summarization. Learning to mimic sample outputs is a common strategy for tackling this kind of issue. This is followed by reinforcement learning to align the model with a reward function. With systems that employ sizable pretrained language models and incentives determined by human input, the NLP industry is now yielding interesting outcomes for tasks that were previously challenging to express.
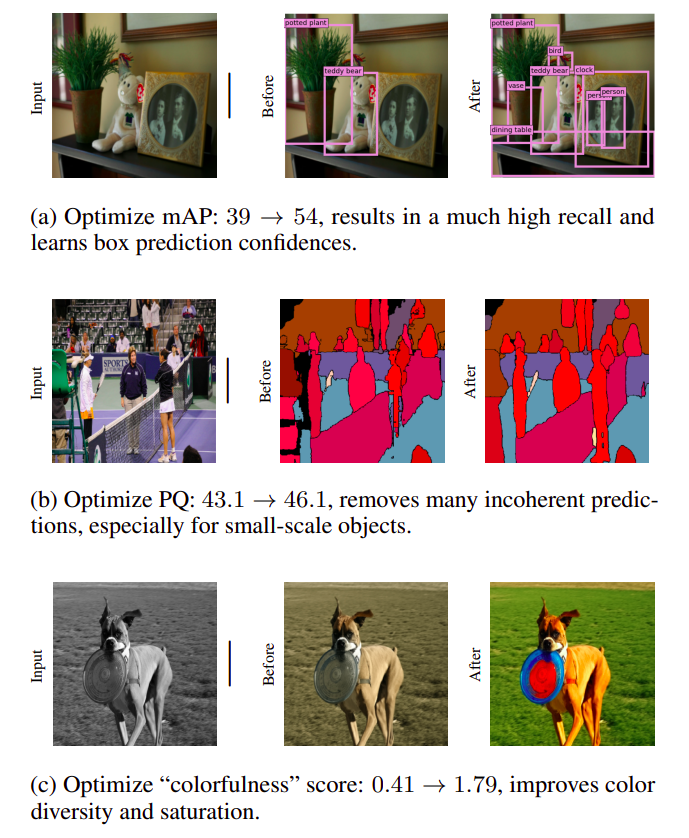
A similar strategy is frequently employed for the picture captioning challenge when CIDEr is given as a prize. Nevertheless, they must be aware of any studies that have looked at reward optimization for (non-textual) computer vision tasks. This study shows that REINFORCE is effective for various computer vision applications right out of the box when used to tune a pretrained model with a reward function. They demonstrate the quantitative and qualitative improvements brought about by reward optimization for object identification, panoptic segmentation, and picture colorization in Figure 1, which highlights some of their important findings.
Their research demonstrates that reward optimization is a practical method for improving a range of computer vision tasks. Their method’s simplicity and efficiency on various computer vision applications prove its adaptability and versatility. But these preliminary results suggest intriguing avenues to optimizing computer vision models with more complicated and difficult-to-express rewards, such as human feedback or holistic system performance, even though they primarily utilize rewards as assessment metrics in this study.
They were able to accomplish the following using the straightforward method of pretraining to mimic ground truth and reward optimization:
- Improve models for object detection and panoptic segmentation trained without other task-specific components to a level comparable to those obtained through deft data manipulation, architectures, and losses.
- Qualitatively alter the results of colorization models to align to create vivid and colorful images.
- Demonstrate that the sim is accurate.
These findings show that it is possible to fine-tune how models match the nontrivial task risk. They look forward to increasingly difficult use cases where they may optimize the perception models for the likelihood of a successful grab, such as optimizing scene understanding outputs for robot grasping.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 14k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.