

Large language models (LMs) are remarkably capable of authoring source code, creating original works of art, and conversing with people. The data used to train the models makes them capable of carrying out these tasks. By enhancing this training data, certain skills can be naturally unlocked. Given a limited amount of training tokens, it is unclear how to choose data from a huge corpus for these capabilities because most existing state-of-the-art LM data selection algorithms rely on heuristics for filtering and combining various datasets. They need a formal framework for describing how data affects the model’s capabilities and how to use this data to boost LM performance.
They drew inspiration from how people learn to create this framework. The notion of abilities that comprise a learning hierarchy is a well-known topic in educational literature. For instance, research revealed that presenting mathematics and scientific concepts in a specific order helped pupils pick them up more rapidly. They want to know how much comparable skill-based orderings characterize LM training. If such orderings exist, they might offer a framework for data-efficient training and a deeper understanding of LMs. For instance, they want to know if training initially on similar but easier tasks, like Spanish grammar and English question creation, helps train an LM for Spanish question generation.
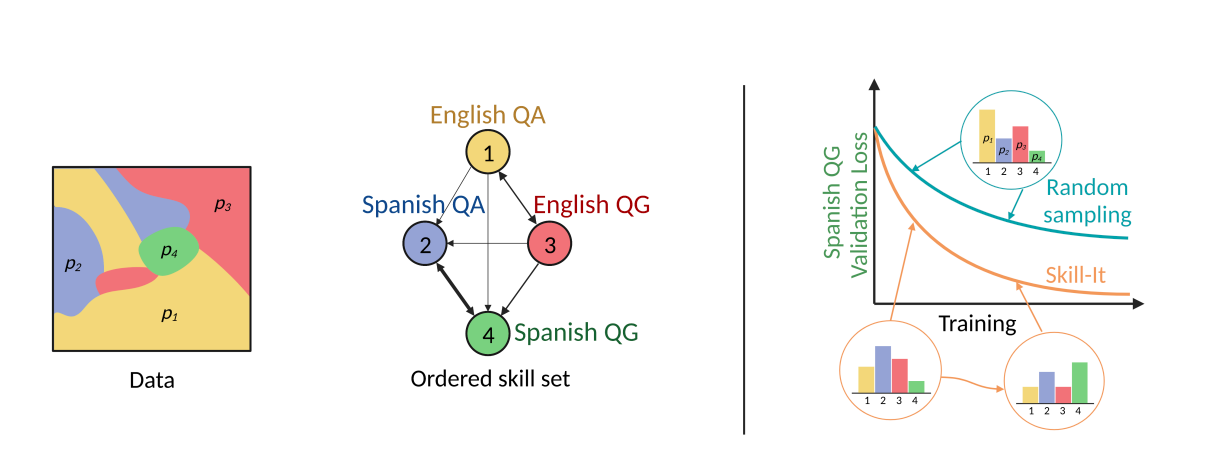
They investigate if the concept of skill orderings may aid in developing a framework that links data to LM training and behavior. To do this, two issues relating to the interaction of data and talents must be resolved. An operational definition of LM skill and skill order must first be defined and tested using data to demonstrate that there are sets of abilities that the LM learns most effectively in a certain sequence. In their early research, they looked at whether semantic groupings of data, such as metadata properties or embedding clusters, could adequately represent a skill and describe the learning process of models.
For example, they partitioned the Alpaca dataset by instruction type to capture dataset diversity. However, they discovered that sampling based on instruction type and random sampling produced models with similar performance, indicating that not just any existing idea of data groups can characterize skills. To truly enhance model training, sample distributions must be built using these definitions of skills. They list difficulties that na?ve selection techniques encounter to create criteria for a data selection algorithm that effectively learns skills. Due to the imbalance and ordering of abilities not being considered in the traditional technique of random uniform sampling across data, learning skills are not optimized.
For example, Spanish and question generation (QG) comprise 5% and 4% of the Natural Instructions dataset, respectively, although Spanish QG is just 0.2%. Skills might be spread unevenly in the data, and more complicated skills are rare. Additionally, random sampling does not offer a way to account for a specific training sequence or skill dependence structure. Sample-level ordering is accounted for by more advanced strategies like curriculum learning but not by skills or their dependencies. These problems of imbalance and order must be considered by their aim framework. A system based on skills As a unit of behavior that a model may learn using an associated slice of data, they define a skill.
An ordered skill set is a group of skills with a directed skills graph that is neither full nor empty, where an edge from a prerequisite skill to a skill exists if the training time required to learn the skill can be shortened if the prerequisite skill is also learned (Figure 1 left, center). Using this operational definition, they demonstrate the existence of ordered skill sets in artificial and actual datasets. Interestingly, these ordered skill sets reveal that learning a talent rapidly requires training on both that skill and necessary skills rather than just that skill alone.
According to their observations, when the model additionally learns English QG and Spanish, they may obtain 4% lower validation loss than training on simply Spanish QG over a set budget of total training steps. Then, using their theory, they provide two approaches to choosing data so that the LM learns skills more quickly: skill-stratified sampling and an online generalization, SKILL-IT. Researchers from Stanford University, the University of Wisconsin-Madison, Together AI and the University of Chicago propose skill-stratified selection, a straightforward method that enables us to explicitly optimize learning skills by uniformly sampling relevant skills (such as a goal skill and its necessary skills in fine-tuning) to solve the issue of unevenly distributed skills in datasets.
Since skill-stratified sampling is static and does not consider the ordering as training progresses, it oversamples abilities that may have been gained earlier in the training process. They propose SKILL-IT, an online data selection technique for picking combinations of training skills, to address this problem by giving higher weight to yet-to-be-learned skills or influential prerequisite skills (Figure 1 right). Assuming a fixed data budget and a skills graph, SKILL-IT is developed from an online optimization problem over the training skills for minimizing loss on a set of assessment skills.
Based on the link between the assessment skill set and the training skill set, SKILL-IT may be modified for ongoing pre-training, fine-tuning, or out-of-domain evaluation. It was inspired by online mirror descent. On artificial and actual datasets, they assess SKILL-IT at two model scales: 125M and 1.3B parameters. On the LEGO simulation, they demonstrated a 35.8-point improvement in accuracy for the continuous pre-training scenario compared to randomly picking training data and curriculum learning. Given the same total training budget, they show that their algorithm over a combination of abilities may achieve up to 13.6% lower loss than training exclusively on that skill in the fine-tuning setting.
Their algorithm can achieve the lowest loss on 11 out of 12 evaluation skills corresponding to task categories in the Natural Instructions test tasks dataset over random and skill-stratified sampling on the training data for the out-of-domain setting where their training skills do not perfectly align with evaluation skills. Finally, they provide a case study using the most recent RedPajama 1.2 trillion token dataset to apply their approach. They continuously pre-train a 3B parameter model utilizing the data mixture generated by SKILL-IT. They discover that SKILL-IT outperforms uniform sampling over data sources with 3B tokens in terms of accuracy with 1B tokens.