Flying a Drone in a Virtual World: This AI Model Can Generate Persistent and Unbounded 3D Worlds
Have you heard of MidJourney, Stable Diffusion, or DALL-E? You probably did if you were paying attention to the AI domain recently. These AI models are capable of generating extremely realistic images that could be tricky to identify from human-generated ones most of the time. It is now possible to achieve remarkable levels of realism with AI-generated images and videos.
Generating a photo-realistic image is possible; we know it. But what if we wanted to do more? What if we actually wanted to be in the image? This is a virtual world, and exploring it freely would’ve been an amazing experience. Picture yourself soaring a drone through a breathtaking virtual world where rivers gush freely, majestic mountains tower above, and trees sway gracefully with the wind. The experience is nothing short of extraordinary, isn’t it? Time to meet Persistent Nature.
Persistent Nature is an unconditional generative model capable of generating unbounded 3D scenes with a persistent underlying world representation.

Persistent Nature builds on top of the advancements in two fields that focus on immersive worlds; 3D models and infinite video models. 3D models represent a consistent 3D world by construction and excel at rendering isolated objects, though they are bounded to indoor scenes. Persistent Nature removes that limitation and tackles the problem of generating large-scale unbounded nature scenes. On the other hand, existing infinitive video models can simulate visual worlds of infinite extent, but they do not ensure a persistent world representation, which is solved by Persistent Nature.
The task is basically moving a virtual camera in a virtual world, though it is not simple to achieve. The content should be generated as we move the camera, and we need to ensure spatial and temporal consistency. If it is not met, the generated output can look like a dream where things move rather strangely, and it is not something we want. Moreover, the generated content should stay the same as we move arbitrarily far and return to the same location, regardless of the camera trajectory.
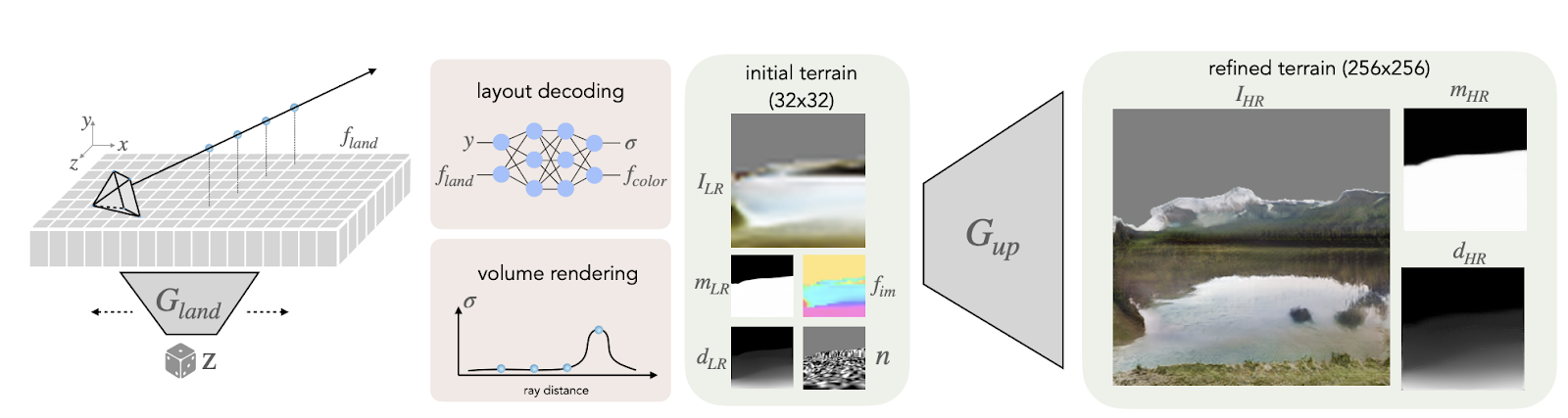
To achieve a persistent nature generation, the proposed approach models the 3D world as a terrain plus a skydome. The terrain is represented by a scene layout grid that acts as a map of the landscape. Then, these features are lifted into 3D and decoded with an MLP into a radiance field for volume rendering. The rendered terrain images are upscaled via super-resolution and composited with renderings from the skydome model to synthesize final images.
Another crucial aspect of the persistent generation is extending the scene. Training the model using the entire landscape is not feasible. Therefore, they train the model using a layout grid of limited size and extend the scene by any amount during inference. This enables unbounded camera trajectories. Moreover, since the underlying representation is persistent over space and time, it is possible o fly around 3D landscapes without needing multiview data. Persistent Nature can be trained entirely from single-view landscape photos with unknown camera poses.
Persistent Nature aims to combine the best of both worlds, generating unbounded scenes while still representing a persistent 3D world. It is an unconditional 3D generative model for unbounded nature scenes with a persistent world representation.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 17k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Ekrem C?etinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.