A general-purpose interface for various natural language activities has been successfully implemented using large language models (LLMs) by a team of Microsoft researchers. An LLM-based interface may be customized for a task as long as the input and output can be converted into text. For instance, a document serves as the input for the work of summarising, and its summary serves as the output. They can feed the input document into the language model to build the produced summary. Despite its many successful uses, natural language processing still has difficulty using LLMs natively for multimodal data, such as pictures and audio. Multimodal perception, a fundamental intelligence component, is required to attain artificial general intelligence regarding knowledge acquisition and connection to reality.
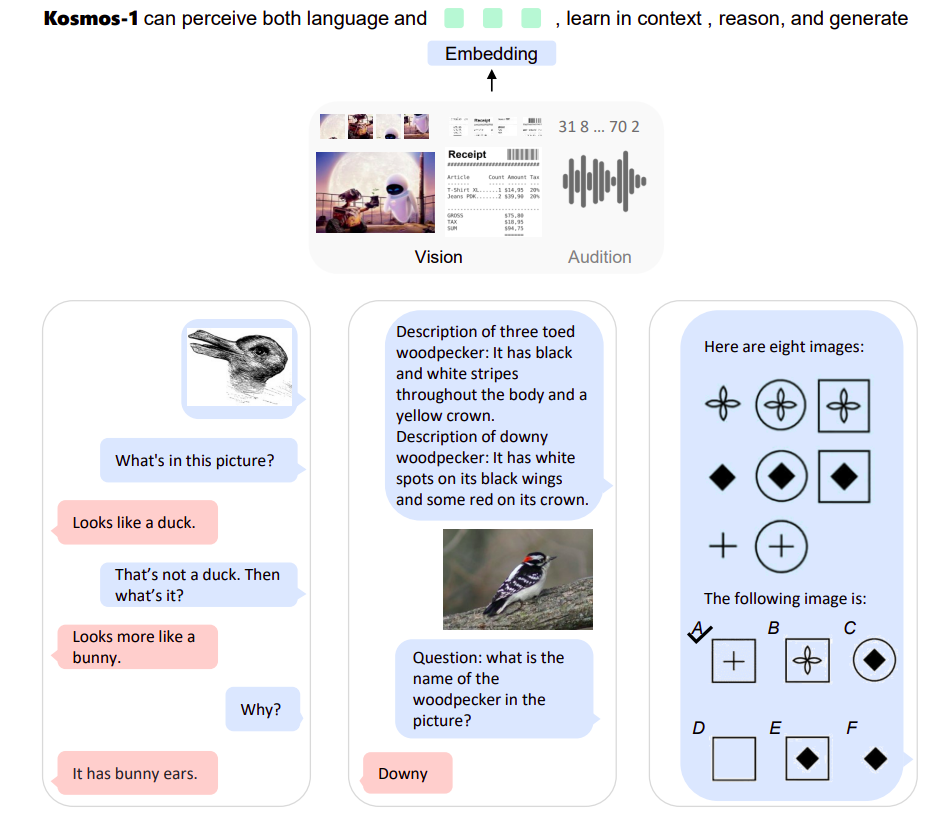
More crucially, by enabling multimodal input, language models may be used in a wider range of high-value fields, including multimodal machine learning, document intelligence, and robotics. In this study, they provide KOSMOS-1, a Multimodal Large Language Model (MLLM) with available modalities perception, zero-shot learning, and context-based learning capabilities (i.e., few-shot learning). The objective is to enable LLMs to see and speak by coordinating perception with those models. To be more precise, they train the KOSMOS-1 model using METALM. The general-purpose interface, as seen in Figure 1, is a language model built on the Transformer framework, and perceptual modules dock with the language model.
The KOSMOS-1 model natively supports language, perception-language, and vision activities, as indicated in Table 1. They use webscale multimodal datasets to train the model, including text data, image-text pairings, and arbitrarily interleaved pictures and words. Moreover, they transmit language-only data to assess the capacity to follow instructions across modalities. The KOSMOS-1 models can naturally handle perception-intensive tasks and natural language tasks. These tasks include visual dialogue, visual explanation, visible question answering, image captioning, simple math equations, OCR, and zero-shot image classification with descriptions.
Also, they developed an IQ test benchmark based on Raven’s Progressive Matrices, which assesses MLLMs’ capacity for nonverbal thinking. The examples demonstrate how there are new chances to use LLMs for novel tasks due to the intrinsic support of multimodal perception. Moreover, they show that MLLMs outperform LLMs in common sense reasoning, demonstrating that cross-modal transfer facilitates knowledge acquisition. Here are the main points to remember: to MLLMs from LLMs. A critical first step towards artificial general intelligence is managing perception properly. LLMs must have the ability to perceive multimodal input.
Firstly, multimodal perception makes it possible for LLMs to learn everyday information beyond written descriptions. Second, perception and LLM alignment pave the way for novel endeavors like robots and document intelligence. Thirdly, because graphical user interfaces are the most intuitive and consistent means of interaction, the capability of perception unites different APIs. For instance, MLLMs can read screens directly or extract numbers from receipts. They use web-scale multimodal corpora to train the KOSMOS-1 models, ensuring that the model can learn from many sources robustly. In addition to mining a sizable text corpus, they employ high-quality picture-caption pairings and web pages with randomly interspersed images and text documents. As general-purpose interfaces, language models.
In addition to sensing modules on difficult tasks, LLMs also function as fundamental reasoners. They view language models as a universal task layer, per the METALM principle. The open-ended output space allows them to combine different task predictions into messages. Moreover, language models can handle natural-language commands and action sequences (such as programming language). The reality, action, and multimodal perception should align with the general-purpose interface, which refers to language models. In addition to the features present in earlier LLMs, MLLMs open up additional applications and opportunities. They can first perform zero- and few-shot multimodal learning utilizing demonstration examples and directions in natural language. Second, they assess the Raven IQ test, gauge people’s capacity for fluid reasoning, and find encouraging signs of nonverbal reasoning. Finally, multi-turn interactions for broad modalities, such as multimodal discourse, are naturally supported by MLLMs. They will soon update their Unified Language Model codebase with KOSMOS-1.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.