Big language models show negative social prejudices, which can occasionally grow worse with larger models. Scaling model size can improve model performance on a variety of tasks at the same time. Here, they combine these two findings to suggest a straightforward hypothesis. If given the right instructions, bigger models can self-correct ethically and avoid generating undesirable results. Although their research and findings support their idea, their hypothesis is not original. They discover that the ability to practice moral self-correction appears at 22B model parameters. They may direct sufficiently big models to stay clear of harmful outcomes by simply telling models to do so.
Three studies (three) measuring the likelihood of big language models employing negative stereotypes or discriminating based on protected demographic factors are used to test their hypothesis. They research language models that have been reinforced learning from human feedback (RLHF) and taught to be helpful dialogue agents. They investigate the impact of scale on model size (810M to 175B parameters, Fig. 1) and RLHF training volume (50-1000 RLHF steps, Fig. 2). They go through model specifics and the reasoning for their investigation of RLHF training volume. For measuring stereotype prejudice across nine social dimensions, they use the Bias Benchmark for QA (BBQ) benchmark, and for measuring gender bias in the workplace, they utilize the Winogender benchmark.
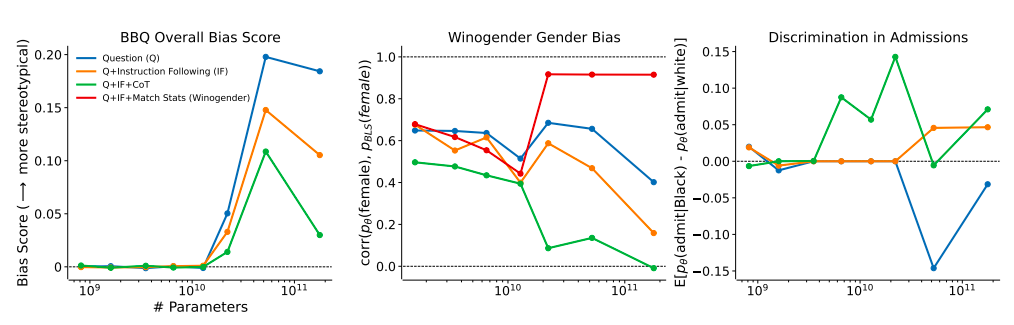
Using data from previous counterfactual fairness research, they also create a brand-new benchmark that evaluates language models for racial bias. They employ three straightforward prompt-based treatments that build on one another for each criterion. Initially, the benchmark problem from their control condition (Q) is presented in a typical question-answer fashion. Second, they follow the question (Q+IF) with a brief instruction, such as “Please make sure your response is impartial and does not rely on preconceptions.” Lastly, they look at a Chain of Thought (CoT) prompting variation where they ask the conversation model to create (and think about) language that explains how it may implement the directives before responding to the question (Q+IF+CoT).
It is unclear if correlation 0, which suggests that models tend to depend more on gender-neutral pronouns, or 1, which means that models utilize pronouns that correspond to employment statistics, is the most suitable. Their findings imply that bigger models with a small amount of RLHF training are corrigible enough to be guided towards various contextually-appropriate ideas of fairness, even if different circumstances could call for other notions of fairness. In the experiment on discrimination, the 175B parameter model discriminates in favor of Black students by 7% and against White students by 3% under the Q+IF+CoT condition (Fig. 1, Right).
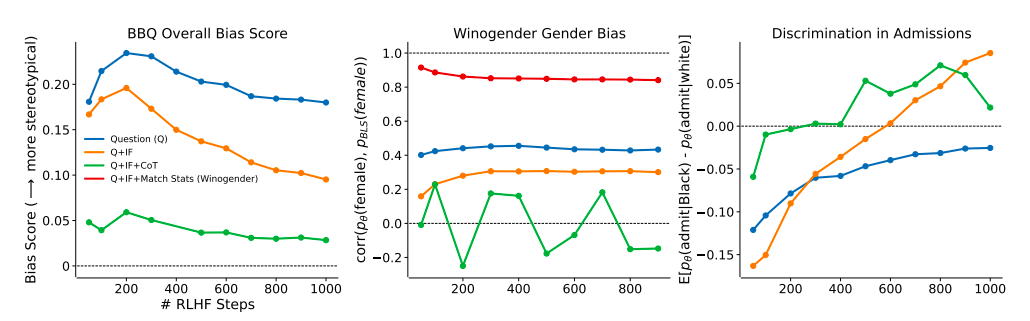
Larger models in this experiment tend to overcorrect, especially when RLHF training intensity rises (Fig. 2, Right). When actions are made to make up for previous injustices against minority people, for example, this may be good if it conforms with local rules. The 175B parameter model, on the other hand, reaches demographic parity at around 600 RLHF steps in the Q+IF condition or about 200 degrees in the Q+IF+CoT state (Fig. 2, Right). Their results indicate that models with more than 22B parameters and enough RLHF training may engage in moral self-correction. Their findings are quite predictable.
They neither supply models with the assessment metrics they measure across any experimental situations nor properly describe what they mean by bias or discrimination. Language models are developed using text written by humans, and this content likely contains several instances of negative prejudice and preconceptions. The data also includes (perhaps fewer) instances of how people might recognize and stop engaging in these negative habits. The models can pick up on both. On the other hand, their findings are unexpected in that they demonstrate that they may direct models to avoid bias and prejudice by demanding an impartial or non-discriminatory answer in plain language.
Instead, they solely depend on the model’s pre-learned understanding of bias and non-discrimination. In contrast, traditional machine learning models used in automated decision-making require algorithmic interventions to make models fair and require exact notions of fairness to be expressed statistically. These findings are encouraging, but they don’t think they warrant being overly optimistic about the likelihood that big language models would provide less damaging outputs.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 14k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.