Diffusion models have caused havoc in image-generation applications in the last couple of months. The stable diffusion led movement had been so successful in generating images from given text prompts that the line between human-generated and AI-generated images has gotten blurry.
Although the progress made them photorealistic image generators, it is still challenging to align the outputs with the text prompts. It could be challenging to explain what you really want to generate to the model, and it might take lots of trials and errors until you obtain the image you desired. This is especially problematic if you want to have text in the output or you want to place certain objects in certain locations in the image.
But if you used ChatGPT or any other large language model, you probably noticed they are extremely good at understanding what you really want and generating answers for you. So, if the alignment problem is not there for LLMS, why do we still have it for image-generation models?
You might ask, “How did LLMs do that?” in the first place, and the answer is reinforcement learning with human feedback (RLHF). RLHF methods initially develop a reward function that captures the aspects of the task that humans find important, using feedback from humans on the model’s outputs. The language model is subsequently fine-tuned using the previously learned reward function.
Can’t we just use the same approach that fixed LLMs’ alignment issue and apply it to image-generation models? This is exactly the same question researchers from Google and Berkeley asked. They wanted to bring the successful approach that fixed LLMs’ alignment problem and transfer it to image-generation models.
Their solution was to fine-tune the method for better aligning using human feedback. It is a three-step solution; generate images from a set of pairs; collect human feedback on these images; train a reward function with this feedback and use it to update the model.
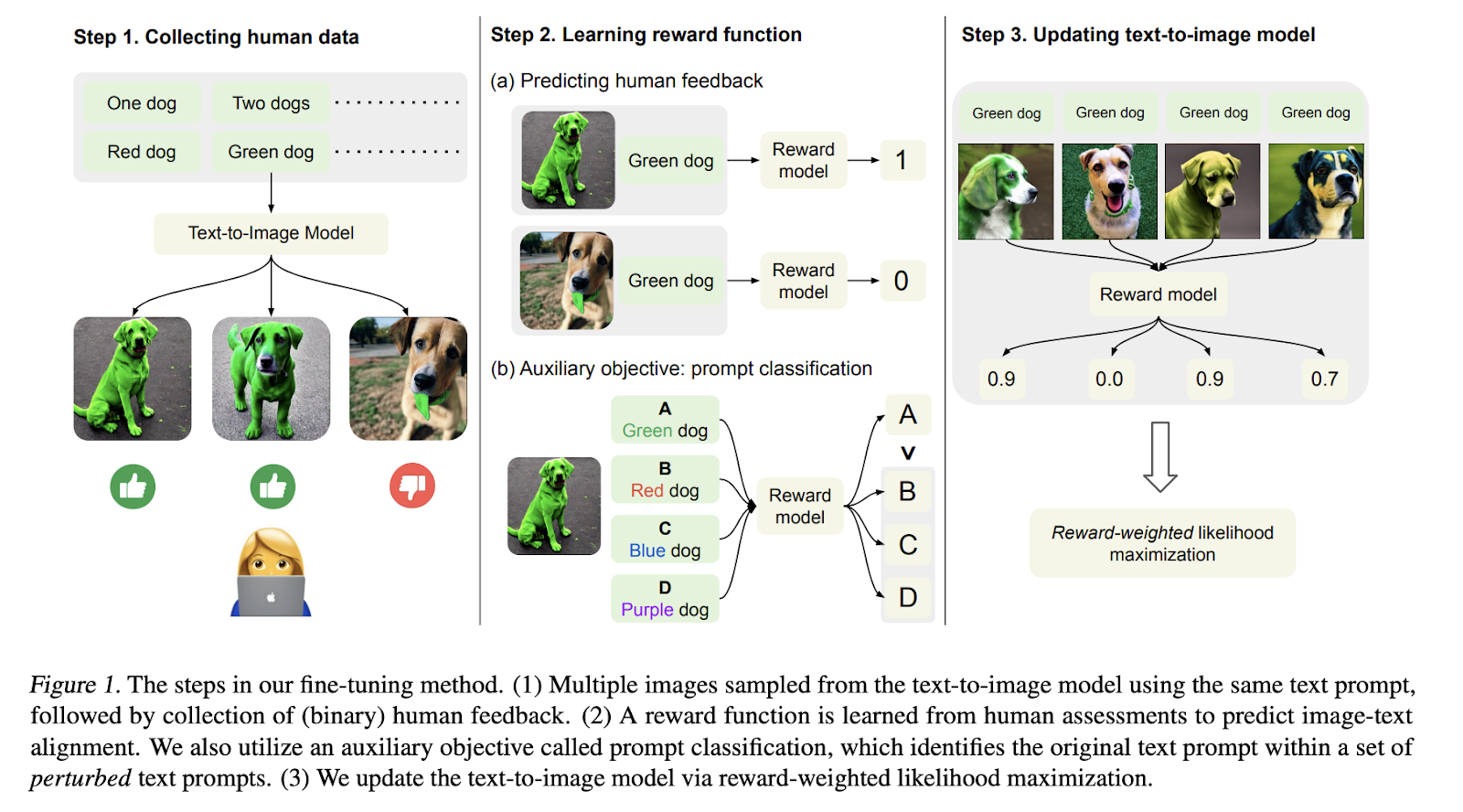
Collecting human data starts with a diverse set of image generation using the existing model. This is specifically focused on prompts where pre-trained models are prone to errors, like generating objects with specific colors, counts, and backgrounds. Then, these generated images are evaluated by human feedback, and each of them is assigned a binary label.
Once the newly labeled dataset is prepared, the reward function is ready to be trained. A reward function to predict human feedback given the image and text prompt is trained. It uses an auxiliary task, which is identifying the original text prompt within a set of perturbed text prompts, to exploit human feedback for reward learning more effectively. This way, the reward function can generalize better to unseen images and text prompts.
The last step is updating the image generation model weights using reward-weighted likelihood maximization to better align the outputs with human feedback.

This approach was tested by fine-tuning the Stable Diffusion with 27K text-image pairs with human feedback. The resulting model was better at generating objects with specific colors and had improved compositional generation.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 16k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Ekrem C?etinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.