In this paper, researchers from OpenAI, who are behind state-of-the-art work on diffusion models, propose “consistency models.” Inspired by diffusion models, they allow for the generation of realistic samples in a single forward pass.
Diffusion models have made spectacular breakthroughs in recent years, surpassing the performance of other generative model families such as GANs, VAEs, or normalizing flows. The general public has been able to witness this through tools such as DALL-E or MidJourney. These models have significant advantages over adversarial approaches, such as more stable training and less susceptibility to the problem of mode collapse. However, the generation of content relies on very deep generative models. Indeed, in a diffusion model, to generate a realistic sample, it is necessary to solve an ordinary (for score-based models) or stochastic differential equation. Formally, this equation can be written as:
Where the term on the right corresponds to the score function of the data, which is estimated via a neural network. We recall that to solve a differential equation of the following form :
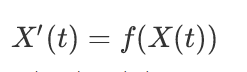
one can use the explicit Euler method, for example:
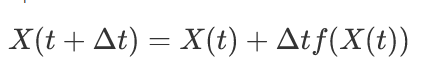
In the case of diffusion models, it is assumed that the data corresponds to final trajectories X(0). For a learned model, generating a sample first involves sampling a Gaussian vector X(T) and then integrating equation (1) backward in time by iteratively stepping through an integration scheme (like Euler above). This numerical scheme can be costly and may require a large number of iterations N (in the literature, N can vary from 10 to several hundred). The goal of this paper is to obtain a generative neural network that requires only a single forward pass.
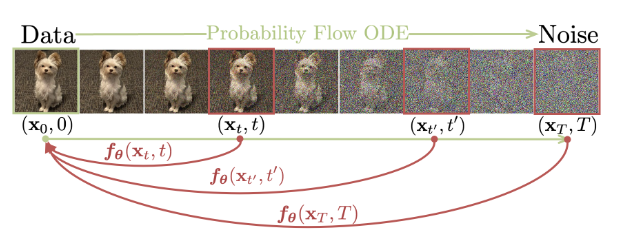
In this paper, the authors propose to learn a neural network F(x,t), which they call a “consistency model,” that satisfies the following properties: for a fixed t, F is invertible. And for any trajectory x(t), F allows for a return to the initial condition, that is:
This property is illustrated in Figure 2.
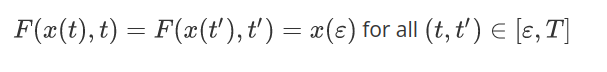
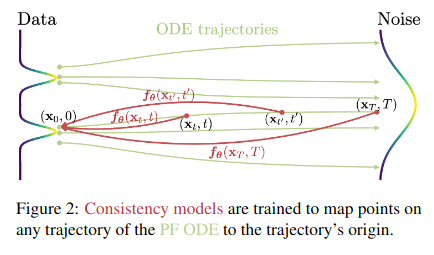
The network F is no longer parameterized by a big ResNet but by an encoder-decoder architecture similar to the U-Net type architecture in the paper “Elucidating the Design Space of Diffusion-Based Generative Model”. Two training configurations are proposed: in the first (training by distillation), it is assumed that a pre-trained diffusion model is already available, allowing the generation of trajectory examples from white noise. The general idea is then to minimize a loss of the following form:
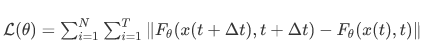
In their second training procedure (by isolation), the idea is the same but does not involve the existence of a pre-trained diffusion model. The training consists of generating X(t) sequences by following the diffusion model’s noise process, i.e., starting from the training data to which Gaussian degradations are applied, as in the diffusion process:
Using these examples, the authors can estimate the score function via a Monte Carlo method. This score function estimator can be used to reproduce an Euler integration scheme and minimize the consistency error introduced earlier. Different experiments are proposed, such as image generation, inpainting, or super-resolution. The experimental protocol is very exhaustive, and the results are very convincing, as the authors outperform competing approaches on the proposed metrics (FID score) and on different datasets (CIFAR, LSUN, ImageNet) in just one forward pass.
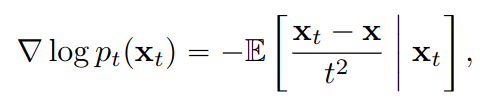
The proposed approach offers several advantages, the main one being its ability to generate realistic samples in just one forward pass. Furthermore, the framework seems flexible since the authors also detail a multi-step procedure to refine the quality of the samples. The gain in terms of required computing resources could open the way to new applications inaccessible to diffusion models.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Simon Benaïchouche received his M.Sc. in Mathematics in 2018. He is currently a Ph.D. candidate at the IMT Atlantique (France), where his research focuses on using deep learning techniques for data assimilation problems. His expertise includes inverse problems in geosciences, uncertainty quantification, and learning physical systems from data.