

In areas with clearly defined reward functions, like games, reinforcement learning (RL) has outperformed human performance. Unfortunately, it is difficult or impossible for many tasks in the real world to design the reward function procedurally. Instead, they must immediately absorb a reward function or policy from user feedback. Furthermore, even when a reward function can be formulated, as in the case of an agent winning a game, the resulting objective may need to be more sparse for RL to solve effectively. Therefore, imitation learning is frequently used to initialize the policy in state-of-the-art results for RL.
In this article, they provide imitation, a library that offers excellent, trustworthy, and modular implementations of seven reward and imitation learning algorithms. Importantly, the interfaces of their algorithms are consistent, making it easy to train and contrast various methods. Additionally, contemporary backends like PyTorch and Stable Baselines3 are used to construct imitation. Prior libraries, on the other hand, frequently supported several algorithms, were no longer actively updated, and were constructed on outmoded frameworks. As a baseline for experiments, imitation has many important applications. According to earlier research, small implementation details in imitation learning algorithms can significantly affect performance.
Imitation seeks to make the process of creating new reward and imitation learning algorithms simpler in addition to offering trustworthy baselines. If a poor experimental baseline is utilized, this can result in falsely positive results being reported. Their techniques have carefully been benchmarked and compared to previous solutions to overcome this difficulty. They also conduct static type checking and have tests covering 98% of their code. Their implementations are modular, allowing users to flexibly alter the architecture of the reward or policy network, the RL algorithm, and the optimizer without modifying the code.
By subclassing and overriding the required methods, algorithms may be expanded. Additionally, imitation offers practical ways to deal with routine activities like gathering rollouts, which helps to promote the creation of whole new algorithms. The fact that the model is constructed using cutting-edge frameworks like PyTorch and Stable Baselines3 is a further advantage. In contrast, many current implementations of imitation and reward learning algorithms were published years ago and have yet to be kept up to date. This is especially valid for reference implementations made available alongside original publications, such as the GAIL and AIRL codebases.
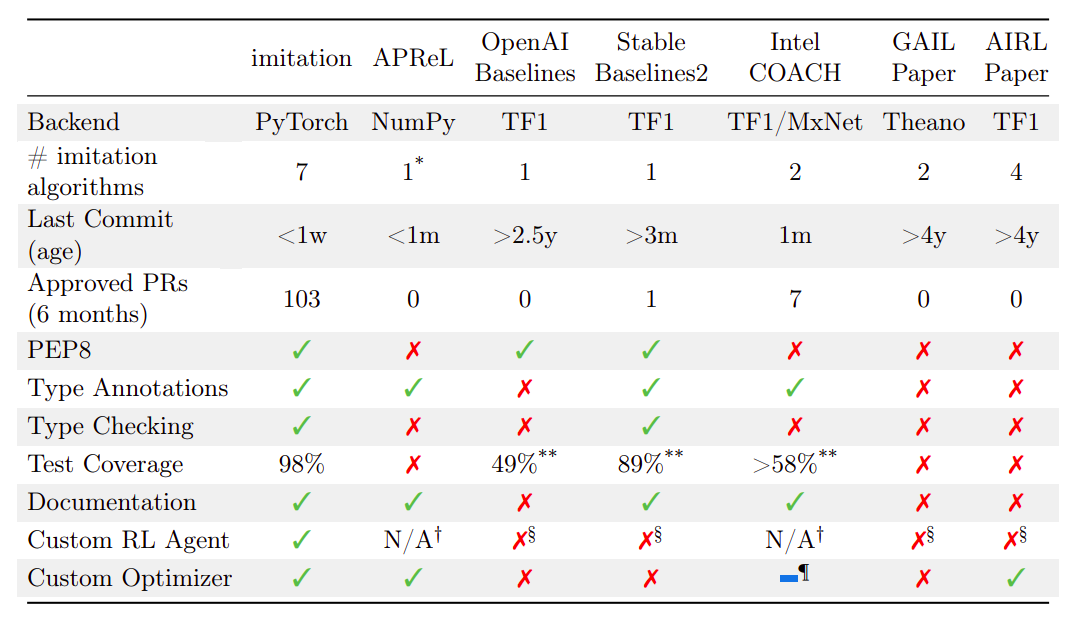
However, even popular libraries like Stable Baselines2 are no longer under active development. They compare alternative libraries on a variety of metrics in the Table above. Although it is not feasible to include every implementation of imitation and reward learning algorithms, this table consists of all widely-used imitation learning libraries to the best of their knowledge. They find that imitation equals or surpasses alternatives in all metrics. APRel scores highly but focuses on preference comparison algorithms learning from low-dimensional features. This is complementary to the model, which provides a broader range of algorithms and emphasizes scalability at the cost of greater implementation complexity. PyTorch implementations can be found on GitHub.