

Deep learning and AI have made remarkable progress in recent years, especially in detection models. Despite these impressive advancements, the effectiveness of object detection models heavily relies on large-scale benchmark datasets. However, the challenge lies in the variation of object categories and scenes. In the real world, there are significant differences from existing images, and novel object classes may emerge, necessitating the reconstruction of datasets to ensure object detectors’ success. Unfortunately, this severely affects their ability to generalize in open-world scenarios. In contrast, humans, even children, can quickly adapt and generalize well in new environments. Consequently, the lack of universality in AI remains a notable gap between AI systems and human intelligence.
The key to overcoming this limitation is the development of a universal object detector to achieve detection capabilities across all types of objects in any given scene. Such a model would possess the remarkable ability to function effectively in unknown situations without requiring additional re-training. Such a breakthrough would significantly approach the goal of making object detection systems as intelligent as humans.
A universal object detector must possess two critical abilities. Firstly, it should be trained using images from various sources and diverse label spaces. Collaborative training on a large scale for classification and localization is essential to ensure the detector gains sufficient information to generalize effectively. The ideal large-scale learning dataset should include many image types, encompassing as many categories as possible, with high-quality bounding box annotations and extensive category vocabularies. Unfortunately, achieving such diversity is challenging due to limitations posed by human annotators. In practice, while small vocabulary datasets offer cleaner annotations, larger ones are noisier and may suffer from inconsistencies. Additionally, specialized datasets focus on specific categories. To achieve universality, the detector must learn from multiple sources with varying label spaces to acquire comprehensive and complete knowledge.
Secondly, the detector should demonstrate robust generalization to the open world. It should be capable of accurately predicting category tags for novel classes not seen during training without any significant drop in performance. However, relying solely on visual information cannot achieve this purpose, as comprehensive visual learning necessitates human annotations for fully-supervised learning.
To overcome these limitations, a novel universal object detection model termed “UniDetector” has been proposed.
The architecture overview is reported in the illustration below.
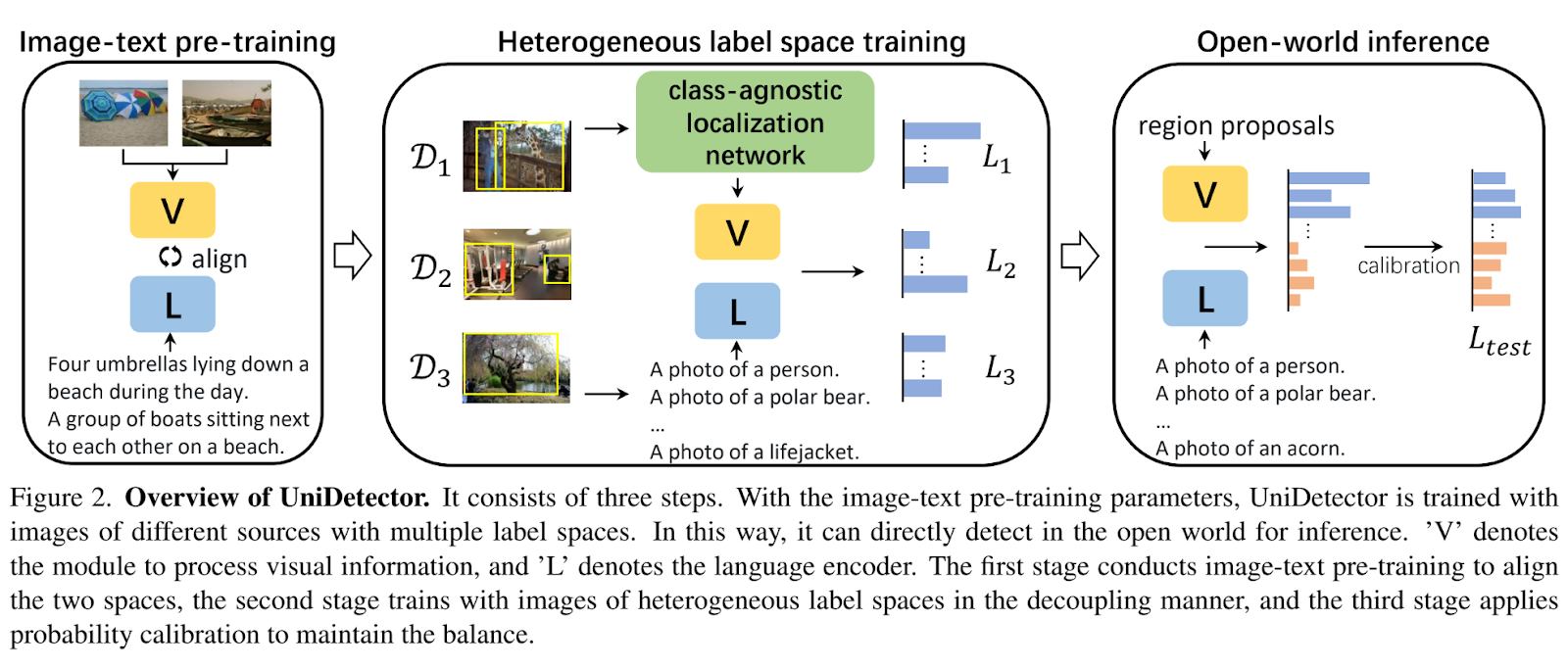
Two corresponding challenges need to be tackled to achieve the two essential abilities of a universal object detector. The first challenge refers to training with multi-source images, where images come from different sources and are associated with diverse label spaces. Existing detectors are limited to predicting classes from only one label space, and the differences in dataset-specific taxonomy and annotation inconsistency among datasets make it difficult to unify multiple heterogeneous label spaces.
The second challenge involves novel category discrimination. Inspired by the success of image-text pre-training in recent research, the authors leverage pre-trained models with language embeddings to recognize unseen categories. However, fully-supervised training tends to bias the detector towards focusing on categories present during training. Consequently, the model might be skewed towards base classes at inference time and produce under-confident predictions for novel classes. Although language embeddings offer the potential to predict novel classes, their performance still lags significantly behind that of base categories.
UniDetector has been designed to tackle the abovementioned challenges. Utilizing the language space, the researchers explore various structures to train the detector effectively with heterogeneous label spaces. They discover that employing a partitioned structure facilitates feature sharing while avoiding label conflicts, which is beneficial for the detector’s performance.
To enhance the generalization ability of the region proposal stage towards novel classes, the authors decouple the proposal generation stage from the RoI (Region of Interest) classification stage, opting for separate training instead of joint training. This approach leverages the unique characteristics of each stage, contributing to the overall universality of the detector. Furthermore, they introduce a class-agnostic localization network (CLN) to achieve generalized region proposals.
Additionally, the authors propose a probability calibration technique to de-bias the predictions. They estimate the prior probability of all categories and then adjust the predicted category distribution based on this prior probability. This calibration significantly improves the performance of novel classes within the object detection system. According to the authors, UniDetector can surpass Dyhead, the state-of-the-art CNN detector, by 6.3% AP (Average Precision).
This was the summary of UniDetector, a novel AI framework designed for universal object detection. If you are interested and want to learn more about this work, you can find further information by clicking on the links below.