

A basic issue in low-level vision is image super-resolution (SR), which aims to recover the high-resolution (HR) picture from the low-resolution (LR) one. Due to the intricacy and unknowable nature of degradation models in real-world circumstances, this problem needs to be addressed. The diffusion model, a recently developed generative model, has seen extraordinary success in creating images. It has also shown significant promise in addressing several downstream low-level vision problems, such as image editing, image inpainting, and image colorization. Additionally, research is still being done to determine how well diffusion models could work for the difficult and time-consuming SR job.
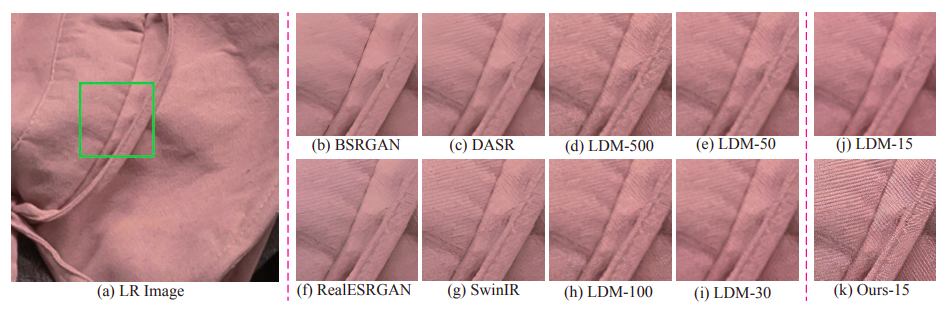
One typical method entails starting from scratch and retraining the model using the training data for SR after introducing the LR picture into the input of the current diffusion model (e.g., DDPM). Another common method is to change the reverse route of an unconditional pre-trained diffusion model before producing the desired HR picture. Unfortunately, the Markov chain that underpins DDPM, which may be inefficient in inference and sometimes need hundreds or even thousands of sample steps, is inherited by both algorithms. The DDIM algorithm is used to speed up the inference in Fig. 1, even though several acceleration approaches have been devised to compress the sample stages in inference. These strategies often result in a considerable reduction in performance and too smooth results.
A novel diffusion model for SR must be created to accomplish both efficiency and performance without compromising either. Let’s review the diffusion model for the creation of images. In the forward process, a Markov chain is constructed over many steps to progressively convert the observed data into a pre-specified prior distribution, often a conventional Gaussian distribution. Then, one may generate images by sampling a noise map from the prior distribution and feeding it into the Markov chain’s backward route. Although the Gaussian prior is a good choice for picture production, it might not be the best option for SR since the LR image is already available.
According to their argument in this study, the appropriate diffusion model for SR should begin with a prior distribution based on the LR picture, allowing for an iterative recovery of the HR image from its LR counterpart instead of Gaussian white noise. A design like this can also lessen the quantity of diffusion steps needed for sampling, increasing the effectiveness of inference. Researchers from the Nanyang Technological University suggest an effective diffusion model that uses a shorter Markov chain to switch between the HR picture and its equivalent LR image. The Markov chain’s beginning state approximates the distribution of the HR picture, while its end state approximates the distribution of the LR image.
They painstakingly craft a transition kernel that gradually adjusts the residual between them to do this. The residual information may be swiftly conveyed in several phases, making this technology more effective than current diffusion-based SR approaches. Additionally, their architecture makes it possible to articulate the evidence lower limit in a clear, analytical manner, simplifying the induction of the optimization goal for training. They create a highly adaptable noise schedule based on this built diffusion kernel that regulates both the residual’s rate of shifting and the noise level in each step.
By adjusting its hyper-parameters, this schedule enables a fidelity-realism trade-off of the retrieved results. In brief, the following are the important contributions of this work:
? They provide an effective diffusion model for SR that, by moving the residual between the two during inference, allows for an iterative sampling process from the undesirable LR picture to the desired HR one. Extensive studies show the advantage of their approach in terms of efficiency, as it only needs 15 simple steps to get desirable results, outperforming or at least being equal to the existing diffusion-based SR techniques that require a protracted sampling procedure. Fig. 1 displays a sneak peek of their retrieved findings compared to existing techniques.
? For the suggested diffusion model, they develop a highly variable noise schedule that enables more exact control over residual and noise levels shifting throughout the transition.